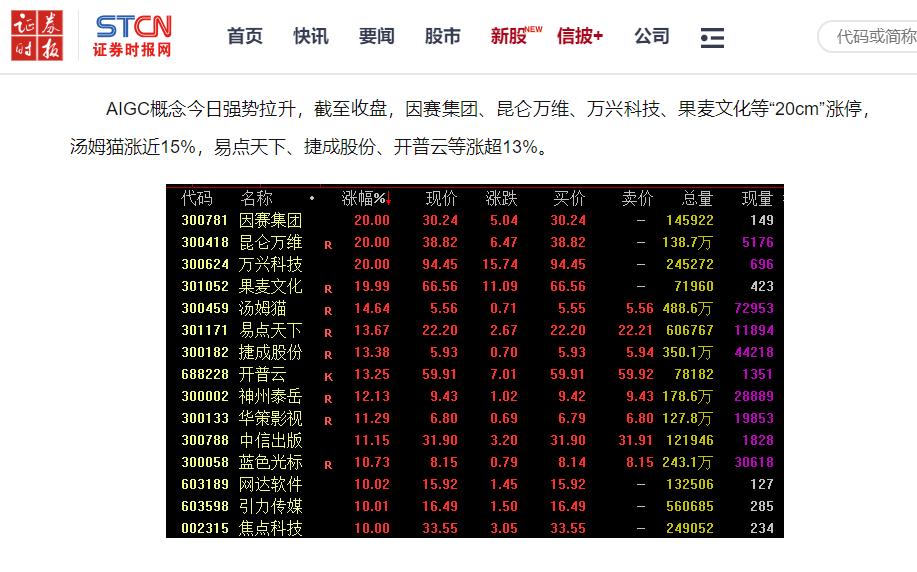
随着本周四晚间美股市场上拼多多的市值超越阿里巴巴,马云直呼“AI电商时代刚刚开始”的消息被疯传。换句话说,拼多多市值超越阿里巴巴,这标志着电商已进入AI(人工智能)时代!在这样的大背景下,周五A股市场上AI电商概念开始横空出世,整个板块上演涨停狂潮,南京商旅(600250)、返利科技(600228)、万兴科技(300624)、因赛集团(300781)、焦点科技(002315)、果麦文化(301052)、昆仑万维(300418)、美登科技(838227)、引力传媒(603598)、中广天择(603721)、苏豪弘业(600128)、网达软件(603189)、南兴股份(002757)、群兴玩具(002575)、良品铺子(603719)、美邦服饰(002269)、启明信息(002232)等十余家AI电商概念股封于涨停!另外,开普云(688228)、汤姆猫(300459)、易点天下(301171)、蓝色光标(300058)、值得买(300785)、神州泰岳(300002)、嘉诚国际(603535)、拓尔思(300229)、新国都(300130)、海天瑞声(688787)等多只AI电商概念股的涨幅也居于涨幅榜前列!由于AI电商的核心技术是AIGC(人工智能生成内容),因此,从本质上来讲,最近横空出世的AI电商概念就是2022年底ChatGPT的出现从而带火的AIGC概念!总之,随着拼多多的市值一举超越阿里巴巴,这标志着电商已进入AI时代,A股市场上的AIGC概念股披上了“AI电商概念”的外衣,从而一跃成为当前市场上最火爆的热点风口。
拼多多市值超越阿里巴巴:马云直呼“AI电商时代刚刚开始”!种种迹象显示,电商已进入AI时代:本周五AI电商概念横空出世上演涨停狂潮
本周二晚间,拼多多发布2023年第三季度财报。财报显示,今年第三季度拼多多的总收入为688.4亿元,同比增长93.9%;归属于普通股东的净收入为155亿元,同比增长47%;拼多多的交易服务收入更是同比增长达315%!在拼多多第三季度财报发布后的一两个交易日内,拼多多的市值就已经超过阿里巴巴,成为在美中概股中的市值第一股。
就在近日,国内多家权威媒体报道称马云在阿里内网中罕见作出回应,表示祝贺拼多多过去几年的决策、执行和努力。尤其是在这次回应中,马云直呼“AI电商时代刚刚开始,对谁都是机会,也是挑战”,进而这则消息被疯传。
引起众多业内人士和资本市场人士注意的是,马云在其留言中,提出了一个新概念——AI电商。
AI电商,顾名思义,指的是通过人工智能技术应用于电子商务领域,从而提升商业运营效率、推动销售增长的商业模式。随着人工智能技术的快速发展和商业需求的变化,AI电商正逐渐成为电商行业的主流趋势。
换句话说,AI电商是指在电子商务领域运用人工智能技术,通过机器学习、数据挖掘、自然语言处理等技术手段,对海量数据进行智能化分析与处理,从而提高商品推荐、用户体验、运营决策等环节的效率和准确度。
应该说,随着科技的迅速发展,我们正从移动互联网时代步入一个全新的时代——AI时代。这个时代不仅是技术发展的一个新阶段,更是商业、社会乃至日常生活模式的一次深刻转变。特别是在电子商务领域,AI时代的到来预示着根本性的变化。
在PC互联网时代,电商主要依靠网页浏览和电子邮件营销。而移动互联网时代,则推动了通过智能手机的购物应用、社交媒体营销和移动支付的普及。相比之下,AI时代的电商,则预示着更加智能化、个性化的购物体验。因此,这一时代的核心特征,是数据驱动和智能化决策的普及,电商企业不再只是提供商品,而是要在理解和满足用户需求上进行更深层次的挖掘。
在AI时代,电商平台不仅是商品的提供者,更成为了用户体验的创造者。这意味着电商企业必须进行战略性的转变,不仅仅是在技术层面上的升级,更是在商业模式、市场定位、用户关系管理等多方面的全面革新。
必须承认的是,人工智能技术的发展,尤其是大模型的应用,正在从根本上改变电商平台的用户体验和交互逻辑。
在移动互联网时代,电商平台的主要交互方式是基于搜索和信息流推荐,辅以短视频和直播等内容形式,以引导用户发现和购买商品。然而,AI时代的电商体验更加注重深入的、个性化的用户交互。当用户登录电商平台时,他们的体验不再局限于搜索商品或浏览信息流,而是与智能助手进行更加自然和深入的对话。
需要指出的是,以大模型为核心的AI技术,不仅仅将变革电商平台的购物体验,还会变革整个电商体系的各个环节,比如通过大数据分析市场需求、供应链优化管理、营销自动化、客服智能化、商品欺诈检测、合规监控等。
事实上,从国内外公司的布局来看,将AI引入电商行业已成为一种全球性趋势。
在海外,亚马逊在2023 AWS纽约峰会上一口气推出七项生成式AI新功能;谷歌已宣布将生成式AI技术引入在线购物工具;微软也宣布了整合Microsoft Shopping功能;Shopify应用商店在3月上旬率先上线一系列ChatGPT应用工具;与Lazada推出电商AI聊天机器人LazzieChat几乎同时,eBay也推出了AI描述生成器,用来生成商品文案……
从国内来看,阿里、京东等互联网大厂在今年“618”期间就已经运用AI技术,阿里妈妈AI创意工具助力内容生产、京东AI数字人助力商品成交/客户服务,今年双十一再次加码;华为云已推出电商智能推荐解决方案,可从海量数据中挖掘用户兴趣,实现精准推荐;百度已上线百度优选智能化助手“小优”,为消费者充当智能导购助手,提供全平台统计的“双十一日历”;小红书也公布了AI智能笔记助手,帮助商家实现商品笔记的一键发布……
上述拥有较高知名度的公司树立起标杆,中小公司同样积极拥抱AI,部分采取借力大公司的方式解锁AI场景,相关案例已经不胜枚举。比如匹克利用阿里妈妈AI工具“万相实验室”制作内容素材,生成的AI商品图成功让新品点击率提升29.8%、加购成本降低27.3%;今年双十一期间,白小T、Ttouchme等诸多国货品牌依靠百度“慧播星”平台提供的数字人,在百度优选24小时直播,GMV提升高达60%,带货效率提升达120%……
因此,天风证券认为,AI生成式电商或是货架电商及推荐电商之后电商行业的新变革。
可见,随着拼多多的市值一举超越阿里巴巴,这标志着电商已进入AI时代!在这样的大背景下,周五A股市场上AI电商概念开始横空出世,整个板块上演涨停狂潮,十余家AI电商概念股封于涨停!种种迹象已充分显示,A股市场上的AI电商概念股已经一跃成为当前市场上最火爆的热点风口。
业内人士:AI电商的核心技术是AIGC(人工智能生成内容)
市场人士分析,从本质上来讲,最近横空出世的“AI电商概念”就是2022年底ChatGPT的出现从而带火的AIGC概念。
AIGC是缩写,全名是指“Artificial Intelligence Generated Content”,即利用人工智能技术来生成内容的一种新型技术,通俗讲是用人工智能进行产品的内容创作。
2022年底,ChatGPT的出现带火了AIGC(人工智能生成内容),近一年来,基于AI生成文案、图像以及视频等内容成为广告主降本增效、探索形而上玩法的利器。AIGC在疯狂的席卷着各行各业,一度被视为全新的生产力革命,在营销行业更是影响颇深。在AIGC加持下,无论是营销创意与AI的碰撞,还是新交互方式的呈现,亦或是分发场景的触达,“营销”都将更有互动性、智能化,更具想象空间,一个全新的AI营销时代已经到来。
如前所述,AI电商是指在电子商务领域运用AI(人工智能)技术,通过机器学习、数据挖掘、自然语言处理等技术手段,对海量数据进行智能化分析与处理,从而提高商品推荐、用户体验、运营决策等环节的效率和准确度。由此可见,AI电商的核心技术是AIGC(人工智能生成内容)!从本质上来讲,最近横空出世的AI电商概念就是2022年底ChatGPT的出现从而带火的AIGC概念!
不得不承认的是,在目前我们所处的AI电商时代,电商营销正在成为AIGC的第一着陆点。今年“双11”购物节,AIGC技术实现了首次大规模落地。
电商巨头、直播电商新秀和社交电商平台三路玩家都入局了。
首先是淘宝天猫和京东正面PK。这厢,淘宝天猫在“双11”期间一口气开放了十几款AIGC免费工具,并用聊天交互检索改变网购玩法;那厢,京东放出首个电商行业大模型,让商家几乎不要钱就能用上一条龙的AI跟单服务,凭空多了一个AI助理。显然,双方展开了全维多点的AIGC比拼。
然后是直播电商新战场,短视频大厂抖音刚刚扔出“即创”这一免费的商家AIGC工具箱,让用户免费地用AI创作视频、图文和直播素材;另一大短视频平台快手就火速上线基于自研“快意”大模型的AI助手,为用户带去各种文生图、文案修改等新体验。AIGC正在成为直播电商的秘密“带货神器”。
社交平台也加入了今年的电商AIGC大试练。生活方式社交平台小红书在“双11”期间推出了AI智能笔记助手,可助商家一键生成标题、正文及图片;购物指南平台值得买科技则把AIGC写进2023年“双11”大促战报:AIGC内容发布量同比提升101.68%,占比近40%;同时其GMV同比增长27.22%。
无论是传统电商还是直播电商,我们看到,AIGC在本届“双11”已经渗透到了从产品上架到售后的方方面面。在这三路玩家的电商卖场中,AIGC已经悄然在广告、内容、社媒、用户增长、创新等各个营销方面渗透,带来新的市场想象空间。
从产业链分布来看,已经有三路玩家在这一领域割据混战,它们分别是:互联网大厂、营销行业龙头和AI企业。
首先是互联网大厂,它们已经圈定AIGC落地的重点方向,并在自己的能力圈强发力。这里既包括阿里、京东、抖音等这些拥有电商业务的大厂,也包括百度、腾讯等其他类的互联网大厂。这类玩家的优势是具有强大的大模型能力、海量算力和数据资源、大量C端用户基础。
第二路玩家是营销行业的专业机构,它们的优势在于靠近客户并具备营销专业知识。营销行业机构的优势在于距离行业场景的距离近,容易触达客户,了解他们的痛点,因此是最容易让AIGC变现的突破口。公开资料显示,包括利欧股份(002131)、蓝色光标(300058)、因赛集团(300781)、三人行(605168)、分众传媒(002027)、易点天下(301171)、宣亚国际(300612)等知名营销行业专业公司都已经推出了AIGC服务。
第三类玩家,则是扎根垂直赛道的AI公司,它们更精通细分领域技术和定制化。目前,国内已经有了非常多AI公司推出了“小而美”的AIGC创新项目,覆盖数字人、智能商拍、视频脚本创作等各个细分领域。AI公司的优势,在于其可以在细分领域将技术产品优化地更极致,比如在效率、个性化、交互或者沉浸感某一个方面做到绝佳,以及提供更加物美价廉的定制化服务。但AI公司的弱势在于缺乏场景和用户基础,为此不少AI创企选择加入大公司生态。
总的来看,以电商为切入点,我们看到了AIGC在营销全领域新市场机遇,覆盖电商、广告、内容、社媒、用户增长、创新等各个方向,这是一个巨大的新市场。而对于掘金营销AIGC领域,互联网大厂、营销行业龙头和一众AI企业都有其优势和劣势,如何扬长避短,也成为它们在这场竞赛中的一大关键。
应该说,面向这一AI电商这一新蓝海,营销行业的专业机构肯定更加为之感到兴奋。毕竟,从目前AIGC落地的场景来看,营销行业是最快与AIGC结合并产生实际落地效果的行业。
2023年5月,利欧股份(002131)率先推出面向营销全行业的AIGC生态平台LEO AIAD;7月,易点天下(301171)首个AIGC数字营销创作平台KreadoAI正式发布;9月12日,蓝色光标(300058)发布营销行业模型“BlueAI”;同日,因赛集团(300781)也于接受调研时表示,预计将于近期推出营销AIGC应用大模型的内测版。
这表明各家营销行业领跑者在营销AIGC领域的探索成果陆续展现,营销 AIGC大模型陆续落地将带来新一轮行业变革。显然,作为最快与AIGC结合并产生实际落地效果的方向,以利欧股份(002131)为代表的营销行业相关头部上市公司,将成为此轮AI电商概念行情的领涨板块。